Crypto AIçáòËÝÙȤDecentralizationƃçáú¯îÄä§ù¼
æ¼íÔȤJacobZhaoÚåÇȤmirrorȘzhaotaobo.eth
åÖAIçáà¨røçÌøÅȘáÈÅëƃòúìYåÇü«¤áæŸÇµÀÂ¥¥ÅgÕT柡ÔçáÙh¿È˜øݧÆQÑ´êùáÈÅëçááÉêÎèüüßécŠHˆÆûÅÏ¿«ÀÈüÁÝàëóâÚŠAÑöçáïpꢥí{ÆûȘƃÔ^°äÅÒ؈°øâmçáǵØáÈùÐêÎëÑàŠÀÂëŠsçáç±äâÚê¼°ä¤ë¡ÔÑàçá£₤ùÐñ´øÏ°øȘòúAIüç§y§´çáíÌí»À¯øÄ¿ÊIÀÝÀÈá¥ÉñÑò§Ú¢ÇȘƃñ§ò§¢èñøÕùáŸÈ¤¥₤øÅ£₤ƃÀÂñøý¥ò§ÆƒÀÂô¯ŸWêØ奯݃öáøÄ■cÆíçáàËøÅÅá£₤ƃÀÈ
¥₤øÅ£₤ƃòú柰ÈØçἧyñ§ò§È˜ÆèöØ£CåÖ݃çÄ¡ÔÅåáÉ¥₤à¤àëõ°èà¨ý¢Æƒê¼°äȘáÆý¥±È´àÓNVIDIAGPUÈˋÀÂçæÆÉ¥±È´CUDAÀÂcuDNNÈˋÀÂ¥₤à¤í{Ñàüç§yÈ´àÓKubernetesÈˋȘç§Æƒ¢·¥ÉÈ´àÓ£ªÆÖNCCL¤µÑùçáPyTorchÈˋùªÆŧM¥±Ñ¥Æè§yØ£çá¢Äøóüç§y fí{Ô\ÅÅÀÈÔ@ñNèŸÑà fë˜çáµwüç§Yò¿çûàÇÌ¿ýüÚÀÂäïÑàë˜ý§¤ëàïÍeCøóçáÅÏôòÔ_ç§æŸ¥îȘñú°ÈÔm¤üGPTÀÂGeminiçàǵØáÈáÈÅëçáƃȘƒÔÆÅÅÏôò¡ÔÀÂìYåÇ¢è¢ÄçáïȘç¨ë˜rÇÌåÖç±éÁÀÂìYåÇÝÖƒÀÂáÉåÇü«¤á¤ëö■cÿLŠUçàŸ}ÀÈ
ñøý¥ò§ÆƒÈ´DistributedTrainingÈˋ òúÛú¯ÇµáÈÅëƃçáø¼ê¼ñ§ò§È˜óð¤ùÅáòúÂáÈÅëƃàöíýާ㤵Șñø¯løêÑÁé_Có¼ fë˜äÅÅȘØåë£óóöCÆùÐécÇÌÎó¢ŸiÀÈÝM¿ÉåÖöÿâÚèüƒÔðÀ¯ñøý¥ò§ÀÝäÄí¼È˜ç¨í«µwàåÆèøÅÅá£₤C¢Äøóí{Ñàécë˜ý§È˜°ÈÔ\ÅÅÆÖ¡ÔùìƒøÆ·ƒWÙhƒ°øÅȘë´Ô^ NVLink ¡Ôùì£Ëô¢ƒ¥¥ÅgȘÆèø¼¿■c§yØ£ fí{¡¼æÆàöíÀÈø¼ê¼ñ§ñ´¯■â´È¤
ç±ýÂÅÅÈ´DataParallelÈˋȤû¢¿■cƃý£ë˜ç± Âç¿ýüÚȘÅÒóËéðáÈÅëÁøÄ
áÈÅëýÂÅÅÈ´ModelParallelÈˋȤÂáÈÅëý£ë˜ý¢ñøý¢òÞåÖý£ë˜¿■cȘ˜FUí¿ÅåÈ£
¿ÉçâýÂÅÅÈ´PipelineParallelÈˋȤñøŠAÑöÇÛÅÅäÅÅȘäáÔëäëôôòÈ£
ê¢ýÂÅÅÈ´TensorParallelÈˋȤƒ¨¥£₤ñø¡ŸƒÄõÆùÐȘäÃè»ýÂÅÅêÈÑàÀÈ
ñøý¥ò§ÆƒòúÀ¯¥₤øÅ¢Äøó+ñøý¥ò§äÅÅÀÝçá§M¤üȘŸÝàë˜Ø£âü¯ÍÔh°äø¡]ÑÁÀ¯ßk¿¨òØÀÝT¿Ê fæ¼ëõ°èàöíÀÈá¢ú¯æ¤¾ùªÆÅø¼ê¼ÇµáÈÅëÈ´GPT-4ÀÂGeminiÀÂLLaMAçàÈˋÑ¥òúë´Ô^Çùñ§ò§ëõ°èƃÀÈ
àËøÅÅá£₤ƃȴDecentralizedTrainingÈˋ tǺÝÚ¡■ƒÔÕ_ñéÅåéc¢¿ýÕäÄÅåçáöÇÚôñ§ÀÈóð¤ùÅáäÄí¼åÖÆÖȤÑÁ£Ëý£Åéàöçá¿■cÈ´¢èáÉòú¥ØÆûŠáXÀÂåóÑùGPU£·Ô ƒåOðÈˋåÖ]ÆÅøÅÅá fí{ó¼çáúÕrüô fë˜ëõ°èƃàöíȘ봰Èë´Ô^ fæh·Æàöíñø¯léc fæ¼È˜ý§Òøº¥ÆûɥʟCøóÇ_ÝÈĨIçáí\ÅåÀÈåáÈò§ûÌéRçáø¼Øˆä¶Þ¯■â´È¤
åOðÛécúÅñøâÏŠyȤÛåOð fí{ŠyÑà¡ÔȘàöíúÅñøÅÏôòçëÈ£
ë´ÅéÅÏôòó¢ŸiȤƒW§jë´Åéý£ñѴȘäïÑàë˜ý§ó¢Ÿiû¼ÿ@È£
¢èÅéäÅÅàÝòÏȤàÝñ΢èÅéäÅÅÙhƒ°È˜ŠyØå·æC¿■còúñþíÌí» ÂécÆùÐÈ£
àÝñΧyØ£ fí{ȤoøÅîŠí{Ñàó¼È˜àöíñø¯lÀÂÛ°È£ÄLCøóëŠsÀÈ
àËøÅÅá£₤ƃ¢èØåâÚ§ãÕȤأà¤à¨ú·çáøƒå¡íÔȘ¡¼æåĨIùÐêÎ fë˜ÆƒáÈÅëȘç¨À¯íÌí»¢èÅÅçáǵØáÈàËøÅÅá£₤ƃÀÝàåòúØ£Úüç§yÅåçá¿Ê°ää¶ÞȘèÌ¥¯üç§y¥ÉÀÂë´Åé fæhÀÂûÉÇa¯ýà¨À§ºCøóÀÂáÈÅë·æCçàÑÁÆûÌȘç¨áÉñþÀ¯ fë˜ÆÅÅÏ+¥ÊŸí\+§Y¿«í»Ç_ÀÝèÅäÆÖåÓóÖåÙÅëä§ù¼ŠAÑöÀÈ
ô¯ŸWêÈ´FederatedLearningÈˋ æ¼Õñøý¥ò§écàËøÅÅá£₤øÛÕgçáÔ^ÑèÅöBȘí{ç±ÝƒçÄÝÈê¶ÀÂáÈÅë Âç¥₤øŃܤüȘÔmÆûÆÖæÂøÄŠ[ù§¤üØçá—ƒ¯È´àÓÃt₤À§ÞàÖÈˋÀÈô¯ŸWêƒÔÆÅñøý¥ò§Æƒçá¿Ê°ä§Y¤ëƒøý¢ fë˜áÉêÎȘë˜r¥ÌƒÔàËøÅÅá£₤ƃçáç±ñøèÂïȘç¨àåØâì¢èÅé fí{ñ§È˜ýÂý£ƒÔðëõà¨Õ_ñééc¢¿ýÕçáäÄÅåÀÈ¢èØå¢Çæ¼òúåÖŠ[ù§¤üØ—ƒ¯üôçáØ£ñNÀ¯òÉ¢ÄàËøÅÅá£₤ÀÝñ§¯¡È˜åÖƃàöíÀÂÅéàö§Yécë´ÅéCøóèüƒªüÁÎĤëȘ¡■Ôm¤üæ¼Õ¿ÊI§ÓÔ^ÑèÅåý¢òÞ¥ÉÀÈAIƃñÑò§à¨ƒ¯ÎÝàÝÚÈ´¥¥Åg¥ÉÀêÅéàö¥ÊŸÀêˆÆûäÄí¼Èˋ

áƃñÑò§Ú¢ÇȘàËøÅÅá£₤ƃýÂý£ÔmÆûÆÖùªÆÅàöíŸÅëÀÈåÖá°Åˋ—ƒ¯øÅȘÆèÆÖàöí§YëŠsÀÂìYåÇÅÒúµO¡Ô£· f漊yÑàǵȘóðäšà£ý£Ôm¤üåÖÛÀÂàËÅéàöçá¿■cøÛÕg¡ÔÅÏëõ°èÀÈâ»àÓǵáÈÅëƃëªëªØâì¡Ôÿ@ÇÌÀÂçëîÆÔtéc¡ÔùìÏȘŠyØååÖÕ_ñéƒW§jøÅÆÅÅÏúÅñøécë˜ý§È£ç±Š[ù§écø¼ÁüßøóçáàöíÈ´àÓÃt₤À§ÞàÖÀÂèÌûÉç±ÈˋòÉüßÆÖñ´ôè¤üØécâÚ¥sò½È˜oñ´Õ_ñé¿ýüÚȣѽàÝñÎ f漥ʟ£ªçAçáàöíÈ´àÓóµIÕ]åÇáÈÅ룷àý¢åÙÅëƃÈˋtàÝèìëãý¢ ÂécÆêÎÀÈÔ@ÅˋÔ §Ó¿ý똰èêùÛú¯àËøÅÅá£₤ƃçá˜FüßøóÀÈ
ç¨Ô@ýÂý£ØãöÑø½àËøÅÅá£₤ƃòúöû■Ÿ}ÀÈòôèüȘåÖ§Yïpê¢ÀÂØæýÂÅÅÀ¢è¥ÊŸçáàöíŸÅëøÅȘàËøÅÅá£₤Æƒí¿˜F°—û¼Ç_çáˆÆûú¯ƒ¯Àȯ■â´ç¨ý£üßÆÖȤLoRAöÂí{ÀÂÅÅÕλRŸ¤µÆƒàöíÈ´àÓRLHFÀÂDPOÈˋÀÂç±Ý¯■ƃécùæÂàöíÀÂìYåÇ¢è¢ÄçáÅÀÅ룪çAáÈÅëƃȘØå¥¯Ô ƒåOð Âécçá fë˜Æƒ—ƒ¯ÀÈÔ@ÅˋàöíóíÝÕƒÔð¡ÔýÂÅÅÅåÀÂçëþŸ¤üÅå¤ëàïàäÛùÐêÎçáäÄí¼È˜ñú°ÈÔm¤üë´Ô^P2PƒW§jÀÂSwarm fæhÀÂñøý¥ò§£₤ó¼çàñ§ò§ÔMÅÅ fæ¼ò§ÆƒÀÈ
àËøÅÅá£₤ƃàöíÔméðÅå¢Æ[ÝÚ

á¢ú¯åÖàËøÅÅá£₤ƃécô¯ŸWêú¯îÄŸIÆ·øÅȘƒÔÆÅǺÝÚÅåçáBlockchainÚá¢ø¼Øˆ¯■â´ PrimeIntellectÀÂPluralis.aiÀÂGensynÀÂNousResearch éc Flock.ioÀÈᥥÅgÅôÅåéc¿Ê°ä˜FŠyÑàÚ¢ÇȘPrimeIntellectÀÂNousResearch¤ëPluralis.ai åÖüç§y¥ÉécùÐñ´åOÆèüäð—êùï^ÑÁåÙÅåä§ù¼È˜ÇºÝÚêùÛú¯âÚíîŃ¢çáú¯îÄñ§ü·È£Ñ½ GensynécFlock.io çá˜Fôñ§üÁÎúÍöºÈ˜ØîáÉ¢Ç称¾ý§çá¿Ê°ä£₤ÔMí¿ÀÈ݃öáÂØâÇö§ãö—Ô@öÍÚá¢Ý°¤µçá¤ùÅᥥÅgéc¿Ê°ä¥ÉôñȘýÂÔMØ£ý§ä§ÆóðåÖàËøÅÅá£₤AIƃµwüçøÅçáýŸÛéc£ËîaõPüçÀÈPrimeIntellectȤƃÉÜE¢è·æCçá£₤Wê f똃W§jüàÅÅíÔ
PrimeIntellectøôêÎÆÖ§´Ø£oÅÒÅéàöçáAIƃƒW§jȘæàö¤öàùÑ¥áÉ ÂécƃȘýÂÎóðÆùÐĨI¨@çû¢èÅéçሟÀÈPrimeIntellectüÈë«ë´Ô^PRIME-RL+TOPLOC+SHARDCASTà»ÇµáÈKȘ§´Ø£ƒÔÆÅ¢è·æCÅåÀÂÕ_ñéÅåÀ¥ʟCøóëõðçáAIàËøÅÅá£₤ƃüç§yÀÈØ£ÀÂPrimeIntellect fæhȧYécõPÌIáÈKrøç

PRIME-RLȤ§ãþŸò§Ûý§£₤Wêàöí¥É
PRIME-RLòúPrimeIntellectÕàËøÅÅá£₤ƃ—ƒ¯Ñ´øóçáàöí§´áÈécäÅÅ¢·¥ÉȘÈÕÛƒW§jécÛý§ ÂécåOÆÀÈù■ýèÆû£₤Wêæ¼ÕüàÔméðÎüµÈ˜ÂƃÀÂëóâÚécÁøÄèü¼Ô^°ä§YÅå§ãþŸÈ˜ò¿û¢Æƒ¿■c¢èØååÖ݃çĈêÂëõ°èàöíîÙÙhȘýÂë´Ô^ùò£₤§Æ¢Öéc·æC¤ëƒÜ¤üCøó fë˜ÀÈüÁÝ༧yÝOѧWêê¼°äȘPRIME-RL¡■Ôm¤üåÖoøÅÅáí{ÑàçáÙhƒ°øŘFÅåƃȘ¥à§ççëêùüç§yëŠsÑàȘØýÕøÏ°øÑÁàöíýÂÅŤëýÔôåîï£₤çšÑ´êù£ªçAÀÈ
TOPLOCȤïpꢥƃÅÅÕ·æCCøó
TOPLOCÈ´TrustedObservation&Policy-LocalityCheckÈˋòúPrimeIntellectäð—çáƃ¢è·æCÅå¤ùÅáCøóȘÆûÆÖéÅÁØ£¿■còúñþíÌçᣪÆÖÆ^yç±ëõ°èêùÆÅÅÏçáýÔôåWêÀÈécZKMLçàøÄÅëñ§¯¡ý£ë˜È˜TOPLOCý£Øâìà¨áÈÅëøÄÆùÐȘѽòúë´Ô^ñøö—À¯Æ^yÅ·êÅýÔôå¡■ÅôÀÝøÛÕgçáƒøý¢Ø£øôÅåÉÜEȘëõ°èïpꢣ₤§Y·æCÀÈù■òæÇöÂƃÔ^°äøÅçáÅÅÕÉÜEßD£₤Õ¢è·æCÎüµÈ˜òú˜FoÅÒÅéàöƃˆŸñøéðçáõPÌIÅôȘէ´¢èÆÀ¢è¥ÊŸçáàËøÅÅá£₤ fæ¼ÆƒƒW§jäÿˋêù¢èÅÅôñ§ÀÈ
SHARDCASTȤÛý§Áøăܤüéc¼ýË fæh
SHARDCASTòúPrimeIntellectåOÆçáÁøļýËécƒÜ¤ü fæhȘÈÕÛý§ÀÂÏòÉüßéc¿■c ŸBÑÁæçáí̃W§jÙhƒ°Ñ½£₤ÀÈù■§Y¤ügossip¼ýËCøóécƒøý¢ë˜ý§ýÔôåȘåòåSÑÁ¿■cåÖý£ë˜ý§ ŸBüô°øâmäç£ý¢ñø¡■ÅôȘ˜FÁøÄçáuÔMò§òí¢écÑÁ¯Ì݃îï£₤ÀÈüÁÝà¥₤øÅò§£·ë˜ý§ò§AllReduceñ§ñ´È˜SHARDCASTÿ@ø½äÃè»êùàËøÅÅá£₤ƃçá¢èUí¿ÅåécàïÍeáÉêÎȘòú§´ñÑ´ÁøÄ¿ýæRéc°øâmƃç■Ǻçá¤ùÅᣪçAÀÈ
OpenDiLoCoȤüÀòÒÛý§ë´Å颷¥É
OpenDiLoCoòúPrimeIntellectFõ £ªÆÖDeepMindäð—çáDiLoCoâÚៈê˜FýÂÕ_åÇçáë´Åé£₤¢·¥ÉȘÈÕàËøÅÅá£₤ƃøÅ°ÈØçáÏòÉüßÀÂåOðÛéc¿■cý£ñÑ´çàä¶ÞѽåOÆÀÈóð¥É£ªÆÖç±ýÂÅÅȘë´Ô^§´RingÀÂExpanderÀÂSmall-WorldçàüÀòÒëÄð§YȘÝÉûãêùਃøë˜ý§çá¡Ôë´ÅéÕ_ðNȘHØâìƒøý¢ÁƒÆ¿■c¥Ç¢èëõ°èáÈÅë fë˜ÆƒÀȧY¤üÛý§¡■ÅôécÁ■càïÍeCøóȘOpenDiLoCoò¿ü«ìM¥GPUécÔ ƒåOðØýáÉñÑ´ ÂécƃàöíȘÿ@ø½äÃè»êùà¨ú· fæ¼Æƒçá¢è ÂécÅåȘòú§´àËøÅÅá£₤ƃƒW§jçáõPÌIë´Å飪çAåOòˋøÛØ£ÀÈ
PCCLȤ fë˜ë´Åéš
PCCLÈ´PrimeCollectiveCommunicationLibraryÈˋ òúPrimeIntellectÕàËøÅÅá£₤AIƃÙhƒ°ê¢èÚÇ·åšçáïpꢥë´ÅéšÈ˜ø¥åÖ§ãQ¼§yë´ÅéšÈ´àÓNCCLÀÂGlooÈˋåÖÛåOðÀÂçëσW§jøÅçáÔméðó¢ŸiÀÈPCCLøÏ°øüÀòÒëÄðÀÂäïÑढsÀÂç냨Ñàë˜ý§écÁ■c£øëȘ¢èÔ\ÅÅÆÖü«ìM¥GPUécý£ñÑ´¿■cȘòúøÏöOpenDiLoCo fæhÛý§ë´ÅéáÉêÎçáçæƧM¥±ÀÈù■ÿ@ø½äÃè»êùƃƒW§jçáÏàïàäÑàécåOð¥ÌàïÅåȘէ´íÌí»Õ_ñéÀÂoÅÒÅéàöçá fë˜ÆƒƒW§jÇ·ë´êùÀ¯æŸ¤µØ£¿¨âÿÀÝçáë´Å飪çAÀÈà»ÀÂPrimeIntellect¥ÊŸƒW§jéc§úè¨ñø¿Ê
PrimeIntellect§´êùØ£oÅÒåS¢èÀ¢è·æCÀƒÔ𧺥ʟCøóçáƃƒW§jȘò¿àö¤öàùÑ¥áÉ Âécàöíý£ªÆÖíÌĨI¨@çûˆŸÀÈ fæhÔ\ÅÅ£ªÆÖໟ¤ùÅá§úè¨È¤
àöí¯lóÞíÔȤѴêxƃÙhƒ°À°¾ò¥áÈÅëÀˆŸ¤₤çéc·æCùò
ƃ¿■cȤäÅÅ݃çÄƃȘäç£ÁøÄ¡■Åô¥¯Æ^yÉÜE
·æC¿■cȤò¿ÆûTOPLOCCøó·æCƃÅÅÕçáíÌÅåȘý ÂécˆŸÆùÐécýÔôåƒÜ¤ü
fæh¤ùÅáê¼°ä¯■â´àöí¯lý¥À¿■cƃÀÂÉÜE·æCÀÂÁøăܤüÈ´SHARDCASTÈˋécˆŸ¯lñéȘ°èØ£ºâ@À¯íÌƃÅÅÕÀÝçá¥ÊŸÕ]ÙhÀÈùáÀÂINTELLECT-2Ȥòæ¢è·æCàËøÅÅá£₤ƃáÈÅëçá¯lý¥
PrimeIntellectÆÖ2025áõ5åô¯lý¥êù INTELLECT-2ȘÔ@òúà¨ú·òæÆèÛý§ÀÂoÅÒÅéàöçáàËøÅÅá£₤¿■c fæ¼ÆƒÑ½°èçá£₤WêǵáÈÅëȘ ÂçØáÈÔ_ 32BÀÈINTELLECT-2áÈÅëÆèÝÕý¥à»Çµøßçá100+GPUÛ¿■c fë˜Æƒëõ°èȘò¿Æûëõà¨Ûý§¥ÉȘƃrÕL°˜400ÅÀrȘí¿òƒ°—Ûý§ f漃W§jçá¢èÅÅÅåécñÑ´ÅåÀÈÔ@Ø£áÈÅëý£HòúØ£ÇöÅåáÉèüçáë£óóȘ¡■òúPrimeIntellectùªäð—À¯Æƒ¥Ç¿ýæRÀÝñÑò§çáòæÇöüç§yôðçÄÀÈINTELLECT-2¥₤°èêù PRIME-RLÈ´Ûý§Æƒ§YÈˋÀÂTOPLOCȴƃÅÅÕ·æCÈˋ éc SHARDCASTÈ´Ûý§ÁøăܤüÈˋ çà¤ùÅá fæháÈKȘùøƒø½àËøÅÅá£₤ƃƒW§jòæÇö˜FêùƃÔ^°äçáÕ_ñé£₤À·æCÅåéc§º¥ÊŸÕ]ÙhÀÈ
åÖÅåáÉñ§ûÌȘINTELLECT-2£ªÆÖQwQ-32BƃýÂåÖǺÇa¤ëçWèüæ—êùÈÕTçáRLƃȘäÆÖÛú¯Õ_åÇRLöÂí{áÈÅëçáú¯îÄùÛòÀÈÝM¿ÉèÅöÇ°˜å§GPT-4£·GeminiçàÕ]åÇáÈÅëȘç¨óðíÌí»çáØãêxåÖÆÖȤù■òúà¨ú·òæëõí«ÆƒÔ^°ä¢èë˜FÀ¢è·æCÀ¢èÆçáàËøÅÅá£₤áÈÅë·ÀÈPrimeIntellectý£HÕ_åÇêùáÈÅëȘ¡■øÄ؈çáòúÕ_åÇêùƃÔ^°ä݃èÚ ÀˆÀˆÆƒç±ÀÂýÔôå¡■ÅôÉÜEÀ·æCê¼°äécƒÜ¤üÔë¡û¼¢èýÕȘ§´êùØ£àùàù¢è ÂécÀ¢èÅé fæ¼À¿ýüÚòíØÌçáàËøÅÅá£₤ƃƒW§jåÙÅëÀÈöÍÀÂFõ écàÖìYÝ°ƒ¯
PrimeIntellectÆÖ2025áõ2åôëõ°è1500àfûâåˆñNæÆïàÖìYȘÆèFoundersFundŸIëÑȘMenloVenturesÀÂAndrejKarpathyÀÂClemDelangueÀÂDylanPatelÀÂBalajiSrinivasanÀÂEmadMostaqueÀÂSandeepNailwalçàÑÁö£ÅÅIŸIÅð ÂëÑÀÈÇùú¯È˜Úá¢ÆÖ2024áõ4åôëõ°è550àfûâåˆåÓóÖïàÖìYȘÆèCoinFund¤ëDistributedGlobal¿ý똟IëÑȘCompoundVCÀÂCollab+CurrencyÀÂProtocolLabsçàCØÁÆÅ ÂécÀȧÄøêá¢ú¯È˜PrimeIntellectâÜÆàÖìYØî°˜Ô^2000àfûâåˆÀÈ
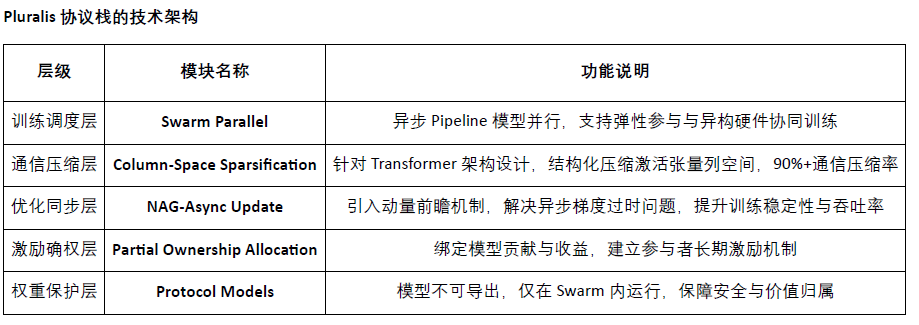
PrimeIntellectçáô¤üò¥àùòúVincentWeisser¤ëJohannesHagemannȘFõ °èTÝ°ƒ¯M¢ÓAIécWeb3ŸIƷȘ¤ùÅá°èTÚæåMetaAIÀÂGoogleResearchÀÂOpenAIÀÂFlashbotsÀÂStabilityAI¥¯Ethereum£ª§Þ±È˜ƒÔðüç§y¥ÉåOÆécñøý¥ò§¿Ê°äôðçÄçá蟤þáÉêÎȘòúÛú¯Oèìç°è¿Îëõ°èíÌàËøÅÅá£₤ǵáÈÅëƃçáäÅÅÅëFõ øÛØ£ÀÈPluralisȤÛý§áÈÅëýÂÅÅéc§Y¤¢s fë˜ÆƒçáñÑò§ä§ù¼íÔ
PluralisòúØ£ÈæÂÆÖÀ¯¢èÅé fë˜ÆƒƒW§jÀÝçáWeb3AIÚá¢È˜óð¤ùÅáá¢ùòúëóÆØ£ñNàËøÅÅá£₤ÀÂÕ_ñéò§ ÂécÀÂýƒÔðÕLó֥ʟCøóçááÈÅëƃñÑò§ÀÈécÛú¯ø¼ê¼¥₤øÅò§£·ñãÕ]ò§Æƒôñ§ý£ë˜È˜Pluralisäð—êùØ£ñNû«Õ ProtocolLearningÈ´ fæhWêÈˋ çáà¨ÅôâÚáŸÈ¤ÂáÈÅëƃÔ^°äÀ¯ fæh£₤ÀÝȘë´Ô^¢è·æC fæ¼Cøó¤ëáÈÅëùªÆÅÁÆ°èðȘ§´Ø£ƒÔðà躥ʟÕ]ÙhçáÕ_ñéƃüç§yÀÈØ£À¤ùÅáâÚáŸÈ¤PotocolLearningÈ´ fæhWêÈˋ
Pluralisäð—çáProtocolLearning¯■¤˜à»ÇµõPÌIøÏøªÈ¤
ý£¢èäÃàÀáÈÅë(UnmaterializableModels)áÈÅëØåùÕó˜Åöò§ñøý¥åÖÑÁ¿■cøÛÕgȘàö¤ööØ£¿■coñ´ÔåÙëõí«ÁøÄÝÈ°øÕ]åÇÀÈÔ@ñNåOÆò¿áÈÅëäšà£°èÕÀ¯ fæhàìYÛaÀÝȘ¢è˜FåL{æC¢ÄøóÀÂëãÅ¿ñâæoécòíØÌwì§Ñ´ÀÈ
£ªÆÖ£ËôƒWçááÈÅëýÂÅÅƃ(Model-parallelTrainingoverInternet)ë´Ô^Ûý§PipelineáÈÅëýÂÅÅCøóÈ´SWARM¥ÉÈˋȘý£ë˜¿■cH°øÆÅý¢ñøÁøÄȘë´Ô^çëσW§j fæ¼ëõ°èƃ£·ëóâÚÀÈ
¯ÇĨIñøéðáÈÅëùªÆÅÁ(PartialOwnershipforIncentives)**ùªÆÅ Âéc¿■c¡ª±óðƃĨI¨@çûáÈÅëý¢ñøùªÆÅÁȘáѽüÚÆÅöÇÚòíØÌñø°è¥¯ fæhøöâÚÁÀÈѱÀÂPluralis fæhÈçᥥÅg¥É
UnmaterializableModels
åÖÀÑAThirdPath:ProtocolLearningÀñøÅòæÇöüç§yäð—ȘáÈÅëÁøÄØåùÕó˜Åöò§ñøý¥È˜ÝÈíüÀ¯áÈÅëìYÛaÀÝø£áÉåÖSwarmƒW§jøÅÔ\ÅÅȘÇ_ÝÈóðåLécòíØ̧åòÉ fæh¢ÄøóÀÈÇùCøóòú˜FàËøÅÅá£₤ƃ¢è°øâm¥ÊŸ§Yçáú¯äÃÀÈ
AsynchronousModel-ParallelTraining
åÖÀÑSWARMParallelwithAsynchronousUpdatesÀñøÅȘPluralis§´êù£ªÆÖPipelineçáÛý§áÈÅëýÂÅÅ¥ÉȘýÂòæÇöåÖLLaMA-3èüÔMÅÅæCÀȤùÅáÅôåÖÆÖØ»àŠ NesterovAcceleratedGradientÈ´NAGÈˋ CøóȘÆÅÅÏÅßí»Ûý§¡■ÅôÔ^°äøÅçáäïÑàó₤Øóécòí¢ý£ñŸ}Șò¿ÛåOðÕgçáƃåÖçëÏÙhƒ°üôƒÔðŠH¢èÅÅÅåÀÈ
Column-SpaceSparsification
åÖÀÑBeyondTop-KÀñøÅäð—Șë´Ô^§Y¡ÅøˆçáêÅ¢íÕg¤¢sñ§ñ´Çºä̼§yTop-KȘÝÉûãóóáíZêxôñ§ÀÈåCøó¥ÌŸáÈÅëòÇ_Ååécë´ÅéÅÏôòȘyåÖÛý§áÈÅëýÂÅÅÙhƒ°øŢ褢s90%Øåèüë´Åéç±È˜òú˜F§Y¡Åøˆ¡ÔÅÏë´ÅéçáõPÌIë£óóÀÈùáÀÂ¥¥ÅgÑ´ö£écôñ§Ôxþ
Pluralisû¼Ç_Øå À¯Ûý§áÈÅëýÂÅÅÀÝ Õ¤ùÅáñ§ü·È˜í{óðüÁï^ÆÖç±ýÂÅŃÔðØåüôïȤ
øÏ°ø çëσW§j éc ñúØ£øôÅå¿■cÈ£
Ôméð åOðÛȘåòåSü«ìM¥GPU ÂécÈ£
äšà£ƒÔð Ååí{Ñà áÉêÎȘøÏ°ø¿■cŸlñÝèüƒ/ŠxƒÈ£
Øå §Y¤¢s+Ûý§¡■Åô+ÁøÄý£¢èäÃàÀÅå Õà»Çµë£óó■cÀÈ
á¢ú¯¡ª±¿ìñ§ƒW탿¨ý¥çáêªóˆ¥¥Ågýˋ¢ëöánȘÔï§Yí«¤üÕØåüôà»ø¼ƒÈ¤
íÉWéc塃¯È¤ÀÑAThirdPath:ProtocolLearningÀñÀÑWhyDecentralizedTrainingMattersÀñ
¥¥ÅgCøó¥¿È¤ÀÑSWARMParallelÀñÀÑBeyondTop-KÀñÀÑAsynchronousUpdatesÀñ
øóÑàÅôä§ù¼È¤ÀÑUnmaterializableModelsÀñÀÑPartialOwnershipProtocolsÀñ
á¢ú¯PluralisèÅöÇèüƒÛaóñÀÂyåƒW£·ÇºÇaÕ_åÇȘåÙØ·åÖÆÖóðùªÔxþçᥥÅgôñ§OƒÔä¶ÞȤÅÒüà§ãQçæÆüç§y¥ÉÀÂë´Åé fæhÀÂÁøÄý£¢èÏ°—çàüç§y¥ŠyŸ}Șýé¢èáÉü·èüñãîbÛaóññ±íÀÈ
åÖ2025áõ6åôPluralisResearch¯lý¥çáÅôíöáøÅȘÂóðàËøÅÅá£₤ƃ¢·¥ÉááÈÅëŸAƃëÄí¿ç§êùáÈÅëöÂí{ŠAÑöȘøÏ°øÛý§¡■ÅôÀÂüÀòÒë´Åéécý¢ñøÁøăܤüȘüÁÝàÇùú¯ó¨øÄâÚíécŸAƃçáåOÆȘ݃Çö¿Ê漡■æÂøÄôðçÄ¢èÅÅÅåȘùøƒø½óðåÖƃà¨øÉóÖ¥ÉèüçáÔMØ£ý§°èòšÀÈöÍÀÂFõ écàÖìYÝ°ƒ¯
PluralisÆÖ 2025áõëõ°èêù760àfûâåˆçáñNæÆïàÖìYȘÆè UnionSquareVenturesÈ´USVÈˋ éc CoinFund ô¤üŸIëÑÀÈò¥àùAlexanderLongÚæåCó¼Wêýˋò¢Ý°ƒ¯È˜ƒÔðçWécüç§yîŃ¢ŠpøÄÝ°ƒ¯ÀȤùÅá°èTà¨ý¢ÆèÚÆÅýˋò¢Ý°ƒ¯çáCó¼WêîŃ¢íÔ§M°èȘòúçðÅëçᥥÅg·ÆÅëÚá¢È˜Øå¡ÔûÉÑàíöáéc¥¥Ågýˋ¢ëÕø¼Øˆ¯lý¥ôñ§È˜Ûú¯èÅöǧ´êÂBD/GrowthFõ ѽÈæÂÆÖ¿Ë¢ùçëÏÛý§áÈÅëýÂÅÅçᣪçA¥ÉŠyŸ}ÀÈGensynȤØå¢è·æCäÅÅ·ÆçáàËøÅÅá£₤ƃ fæhÆ
Gensyn òúØ£ÈæÂÆÖÀ¯èŸÑàWêƃàöí¢èÅéäÅÅÀÝçáWeb3AIÚá¢È˜¤ùÅáý£åÖÆÖøÄáÈÅë¥É£·ÆƒñÑò§È˜Ñ½åÖÆÖ§´Ø£ƒÔðÀ¯àöíñø¯l+ƃäÅÅ+§Y¿«·æC+¿¨ó§¥ÊŸÀÝà¨ê¼°äçá¢è·æCñøý¥ò§ÆƒäÅŃW§jÀÈë´Ô^Ìüôƃ+Ìèü·æCçá¥ÉåOÆȘGensyn§´êÂóÞØ£¡ÔÅÏÀÂÕ_ñéÀ¢è¥ÊŸçáà¨ú·ÆƒòŗȘò¿À¯Æƒ¥ÇMiningÀÝ°èÕ˜FÀÈØ£ÀÂÚá¢Ñ´ö£È¤ÆƒàöíçáäÅÅ fæhÆ
Gensyný£òúÀ¯å¾ûÇƃÀÝȘѽòúÀ¯ÆèílƃÀÂàÓ¤ö·æCÀÂàÓ¤öñøÀÝçᣪçAåOòˋÀÈóð݃ì|òúƃàöíçá¢è·æCÆùÐ fæhȘóðø¼Øˆ§ãQȤ
ílÚäÅÅƃàöíÈ´ùÐêÎñø¯lécÆBóËéðÈˋ
àÓ¤ö·æCäÅŧY¿«È´oÅÒà¨øÄùÐȘH·æC æhùÐæÆÈˋ
àÓ¤öñøéðƃòíØÌÈ´StakeÀÂSlashingécÑÁ§úè¨ýˋßáCøóÈˋѱÀÂ¥¥Åg¥É¢Æ[
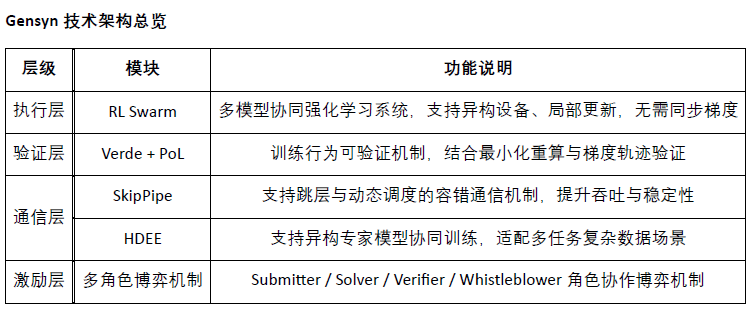
RLSwarmȤ f똣₤Wêƃüç§y
GensynòæçáRLSwarm òúØ£ñNûÌü·¤µÆƒŠAÑöçáàËøÅÅá£₤ÑÁáÈÅë f똣₤üç§yȘƒÔðØåüô¤ùÅáäÄÅåȤ
ñøý¥ò§ëóâÚécWêê¼°äȤ
躰èŠAÑöÈ´AnsweringÈˋȤû¢¿■cˆêÂï°—ÇÞ¯¡È£
éºåuŠAÑöÈ´CritiqueÈˋȤ¿■c£ËüÁ■cåuù«àùﰗȘÔx°—æŸÇÞ¯¡écÔïÈ£
¿ýæRŠAÑöÈ´ResolvingÈˋȤŸAyǵÑÁç¿■có¨¤ûý±ÇùÅß¡áæåèÚ£ÄÇÞȘ˜Fƒøý¢ÁøÄ¡■ÅôÀÈ
Gensynùªäð—çáRLSwarmòúØ£àËøÅÅá£₤çáÑÁáÈÅë f똣₤üç§yȘû¢¿■cÔ\ÅňêÂáÈÅëýÂÔMÅÅ݃çÄƃȘoÅÒäïÑàë˜ý§È˜äšà£ÔmˆÛùÐêÎécý£ñÑ´ƒW§jÙhƒ°È˜ë˜røÏ°ø¿■cÅå§ÆàŠécëù°—ÀÈåCøó§ÒÒbRLHFécÑÁøúáɵwýˋßáçáù¥ôñȘ稡■ìN§■ fë˜ëóâÚƒW§jçáÆBîï£₤ÔïȘ¿■c¡ª±écवw¿ýæR§Y¿«çáØ£øô°äÑà¨@çûˆŸÈ˜áѽ·ÆëóâÚáÉêÎçá°øâm£₤écÖ ë˜WêÀÈRLSwarmÿ@ø½äÃè»êùáÈÅëåÖÕ_ñéƒW§jüôçáñ§ÀÅåécñ¤£₤áÉêÎȘØîæ¼Õ¤ùÅáäÅÅáÈKôòüàåÖGensyn£ªÆÖEthereumRollupçá TestnetPhase0 øÅý¢òÞèüƒÀÈ
Verde+Proof-of-LearningȤ¢èÅé·æCCøó
GensynçáVerdeáÈK§Y¤üêùà»ñNCøóȤ
Proof-of-LearningȤ£ªÆÖäïÑàÉÜEécƃåˆç±éÅÁƃòúñþí̯lèºÈ£
Graph-BasedPinpointȤѴö£ÆƒÆùÐDøÅçáñøóÓ¿■cȘHÅÒøÄùЃԵwýìæ¼È£
RefereedDelegationȤýèÆûøìýûò§·æCCøóȘÆèverifierécchallengeräð— æhýƒøý¢·æCȘOǵ§ççë·æC°è݃ÀÈ
üÁï^ÆÖZKP£·à¨øÄùзæCñ§¯¡È˜Verdeñ§¯¡åÖ¢è·æCÅåécÅÏôòøÛÕgàÀçû¡■ó§¤ãÀÈ
SkipPipeȤë´ÅéàïÍe£₤Cøó
SkipPipeòúÕêù§ãQÀ¯çëÏ+¿■c綃ÀÝ—ƒ¯üôçáë´Åéó¢ŸiŸ}Șóð¤ùÅááÉêί■â´È¤
ä½ÆCøóÈ´SkipRatioÈˋȤä½Ô^òÉüß¿■cȘÝÉûãƃæÒà«È£
ÆBí{ÑàùÐñ´È¤r躰èæŸäÅÅôñ§È£
àïÍeäÅÅȤ¥Çò¿50%¿■còÏÅÏȘëóâÚƒ¨ÑàHüô§ç¥s7%ÀÈ
øÏ°øƃëäëôäÃ軡ÔÔ_55%Șý˜FÀ¯early-exitëóâÚÀÝÀÂÀ¯o¢pøÄééÀÝÀÂÀ¯ëóâÚîaà¨ÀÝçàõPÌIáÉêÎÀÈ
HDEEȤ¢ÓŸIÆ·Ûȥإ₤à¤
HDEEÈ´HeterogeneousDomain-ExpertEnsemblesÈˋáÈKøôêÎÆÖ£₤Øåüô—ƒ¯È¤
ÑÁŸIÆ·ÀÂÑÁáÈBÀÂÑÁàöíƃȣ
¡¼ŸÆƒç±ñøý¥ý£ƒª¤ãÀŠyÑàýŸÛǵȣ
åOðÆùÐáÉêÎÛÀÂë´ÅéÏý£Ø£øôçáÙhƒ°üôàöíñøéðécí{ÑàŸ}ÀÈ
óð¤ùÅáäÄÅåȤ
MHe-IHoȤÕý£ë˜ŠyÑàçáàöíñøéðý£ë˜ÇµÅÀçááÈÅëÈ´áÈÅëÛÀÂƃý§ÕLØ£øôÈˋÈ£
MHo-IHeȤàöíŠyÑà§yØ£ÀÂç¨Æƒý§ÕLÛý§í{í«È£
øÏ°øÛÈ¥ØáÈÅë+¢èýͯöƃýÔôåȘäÃè»ÔmˆÅåécàïÍeÅåÈ£
í{À¯ýÂÅÅ fë˜+Oçëë´Åé+ÆBÈ¥ØñøéðÀÝȘÔmÆûÆÖ˜FøÅëŠsçáàöíèºBÀÈ
ÑÁ§úè¨ýˋßáCøóȤÅéàöéc¥ÊŸýÂÅÅ
GensynƒW§jØ»àŠù០ÂécíÔȤ
SubmitterȤ¯lý¥ÆƒàöíÀÂåOÑ´§YécŸAùÐÈ£
SolverȤäÅÅƃàöíȘä磧Y¿«È£
VerifierȤ·æCƃÅÅÕȘÇ_ÝÈóð¤üØÆÅÅÏÈ£
WhistleblowerȤä¶Þ·æCíÔȘ¨@àÀøìýûˆŸ£·°ÅºêP]ÀÈ
åCøóš`¡ÅÚåÇÆÖTruebit§ºýˋßáåOÆȘë´Ô^øóýÍàŠÍeí`+ŠSCøìýûȘ¥ÊŸ ÂécíÔí\ fæ¼È˜Ç_ÝȃW§j¢èÅéÔ\ÅÅÀÈùáÀÂyåƒWécôñƒDØ
GensynÆèBenFielding¤ëHarryGrieveô¤üêÂȘ¢ý¢ö£ÆÖƽÑÄÀÈ2023áõ5åôȘGensynÅ«ý¥ëõ°èÆèa16zcryptoŸIëÑçá4,300àfûâåˆAïàÖìYȘóðù«ëÑìYñ§¯■â´CoinFundÀÂCanonicalÀÂEtherealVenturesÀÂFactor¤ëEdenBlockÀÈFõ Ý°ƒ¯àÖ¤üñøý¥ò§üç§yécCó¼Wê¿Ê°ä§·È˜ÕLóÖøôêÎÆÖ§´¢è·æCÀÂàËÅéàö£₤çáǵØáÈAIƃäÅŃW§jÀÈNousResearchȤø¼µwÅåAIâÚ៷ÆçáíJøˆîï£₤ò§Æƒüç§y
NousResearch òúá¢ú¯èìç¥ÌƒÔíÉW¡ÔÑàéc¿Ê°ä˜FçáàËøÅÅá£₤ƃFõ Șóð¤ùÅá塃¯åÇÆÖÀ¯DesideraticAIÀÝâÚáŸÈ¤ÂAIØÕƒÔÆÅø¼Æ^Ååécîï£₤áÉêÎçáøúáÉø¼µwȘѽñúö¥çá¢è¢Ä¿ÊƒÔÀÈNousResearchçáˆäÄÅååÖÆÖȤù■ý£òúÂAIƃÛæ¼À¯ÅÏôòŸ}ÀÝÚ£₤ȘѽòúÂóðØÕÀ¯íJøˆø¼µwÀÝçáÅö°èÔ^°äÀÈåÖÔ@أ塃¯·ÆüôȘNousƒÜ§¿§´Ø£ÆèÛ¿■c fë˜ÆƒÀÂoÅÒøÅÅáí{ÑàÀ¢袿ýÕ·æCçáÕ_ñéò§ÆƒƒW§jȘýÂë´Ô^à¨Èò§¿ÊƒÔÌÔMÅÅüç§y£₤ôðçÄÀÈØ£ÀÂâÚáŸøÏöȤøÄÅôÑ´êxƃçáÀ¯á¢çáÀÝ
NousýÂöÇå֥ʟåOÆ£· fæh§ºWèüëÑàŠÔ^ÑÁȘѽòúåD¡áæƃ݃èÚçáíÉWú¯äÃȤ
ñÇÎÀ¯alignmentismÀÝȤý£íJë˜ØåàùŸ¢ÄøóÕö´Ø£á¢ùçáÀ¯í{§äò§ÆƒÀÝȘø¼Æƒˆ¿áŸáÈÅëÅö°èˆêÂíJøˆÿL¡þÈ£
í{áÈÅëø¼µwÅåȤíJÕ£ªçAáÈÅëˆÝÈê¶ý£Ç_Ñ´ÅåÀÂÑÁÆÅåéc£ûÆX躰èáÉêÎÈ´hallucinationasvirtueÈˋÈ£
áÈÅëƃ¥ÇíJøˆÅö°èȤáÈÅëý£òúÀ¯£₤àöíëõ°èÑàÀÝȘѽòú ÂécíJøˆîï£₤Ô^°äçáµwÀÈ
Ô@أƃÆ^Šmà£À¯âùô±ÀÝȘç¨ñÇÆ°°—NousåOÆƃ£ªçAåOòˋçá¤ùÅáÔïȤàÓ¤öæÛáÈÅëåÖÕ_ñéƒW§jøÅîï£₤ȘѽñúÝ£§yØ£ØÆÀÈѱÀÂƃ¤ùÅáȤPsycheƒW§jécDisTrO£₤ó¼
NousÎàËøÅÅá£₤ƃæŸõPÌIçáĨIȘòú§´êù PsycheƒW§j écçæÆë´Åé£₤ó¼ DisTrOÈ´DistributedTrainingOver-the-InternetÈˋȘ¿ý똰èƃàöíçáäÅÅøÅÅȤDisTrO+PsycheƒW§jƒÔðÑÁÚ¤ùÅááÉêÎȘ¯■â´ë´Å餢sÈ´ýèÆûDCT+1-bitsignƒÇaȘOǵ§ççëÏÅÒúµÈˋÀ¿■cÔméðÅåÈ´øÏ°øÛGPUÀÂÁƒøÄÔBécæåø¼ëù°—ÈˋÀÂÛý§àïÍeÈ´oÅÒë˜ý§ØÁ¢è°øâmƃȘƒÔð¡ÔàïÍeÅåÈˋÀÂØ奯àËøÅÅá£₤í{ÑàCøóÈ´oÅÒøÅÅá fí{ó¼È˜£ªÆÖBlockchain˜F¿ýæRécàöíñø¯lÈˋÀÈÔ@Ø£¥ÉÕçë°è݃ÀÂÅåÀ¢è·æCçáÕ_ñéƃƒW§jäÿˋêù˜F¢èÅÅçᥥÅg£ªçAÀÈ
HermesÕ_åÇáÈÅëüçêÅȤHermes1øê3òúNousëó°—çáǺÝÚÅåÕ_åÇǵáÈÅëȘ£ªÆÖLLaMA3.1ƃȘ¤Ùèw8BÀÂ70B¤ë405Bà»ñN ÂçØáÈÀÈåüçêÅø¥åÖµw˜FNousùª°¨ÏçáÀ¯àËø¡êŸ£₤ÀÂÝÈê¶ÑÁÆÅåÀÝƃâÚáŸÈ˜åÖÕLèüüôöáÝÈ°øÀ§ú訯ÓîïÀÂÑÁïÎåçàñ§ûÌí¿˜F°—¡■çáÝÚÔ_êÎécñ¤£₤áÉêÎÀÈ
ForgeReasoningAPIȤÑÁáÈò§ëóâÚüç§yForgeòúNousæåîÅçáëóâÚ¢·¥ÉȘ§Y¤üà»ñN£ËîaCøóØå˜F¡■ƒÔÅåécåšêÎçáëóâÚáÉêÎȤMCTSÈ´MonteCarloTreeSearchÈˋȤÔmÆûÆÖëŠsàöíçáýÔôåùîù¼È£CoCÈ´ChainofCodeÈˋȤػàŠÇºÇaÌécÔïëóâÚçá§Y¤üôñ§È£MoAÈ´MixtureofAgentsÈˋȤåòåSÑÁáÈÅëÔMÅÅ fèäȘäÃè»ï°—çáVÑàécÑÁÆÅåÀÈåüç§yí{À¯ñúÇ_Ñ´ÅåëóâÚÀÝéc§M¤üò§èº°èôñ§È˜òúμ§yø¡êŸÎ»RñÑò§çáÆÅêΣĈÀÈ
TEE_HEEȤAIæåø¼ÇºâڷȤTEE_HEEòúNousåÖæåøöǺâÚñ§ü·çáú¯îÄä§ù¼È˜ø¥åÖ·æCAIòúñþáÉ·åÖ¢èÅéäÅÅÙhƒ°È´TEEÈˋøňêÂÔ\ÅÅýÂÚÆÅö´Ø£çáçæøèÚñïÀÈåǺâÚƒÔðÈìçáTwitter¤ëEthereumì~¶È˜ùªÆÅ¢ÄøóÁüßÆèÔh°ä¢è·æCçáenclave¿ÉâÚȘÕ_¯líÔoñ´¡èŸAóðÅÅÕÀÈ·á¢ùòú§´ƒÔðÀ¯ý£¢èÇÜ¡áÅåÀÝécÀ¯ˆêÂÅÅÕØãDÀÝçáAIø¼µwȘÔ~°—§´æåøöÅëøúáɵwçáøÄ؈أý§ÀÈ
AIÅÅÕáÈMó¼ó§é_ȤNousÔÕ_¯lêù¯■â´WorldSimÀÂDoomscrollÀÂGods&S8nçàÑÁáÈMó¼È˜ÆûÆÖîŃ¢AIåÖÑÁ§úè¨èÓ±Ùhƒ°øÅçáÅÅÕîï£₤écrøçÅö°èCøóÀÈÝM¿Éý£øÝ§Æ Âécƃ꼰äȘÔ@Åˋ·ÕÕLóÖæåøöAIçáíJøˆÅÅÕ§´áÈçšÑ´êùíZêxÆ£ªçAÀÈùáÀÂFõ écàÖìY¡érNousResearch°èêÂÆÖ2023áõȘÆèJeffreyQuesnelleÈ´CEOÈˋÀÂKaranMalhotraÀÂTekniumÀÂShivaniMitraçààùô¤üßkÀÈFõ ØåíÉW·Æécüç§y¿Ê°äýÂøÄȘÚÆÅCó¼WêÀÂüç§y¯ýà¨ÀÂàËøÅÅá£₤ƒW§jçàÑÁåˆÝ°ƒ¯ÀÈ2024áõ¨@çû520àfûâåˆñNæÆïàÖìYȘ2025áõ4åôȘëõ°èÆèParadigmŸIëÑçá5,000àfûâåˆAïàÖìYȘ¿âøçÔ_10|ûâåˆÈ˜ÉQèÚWeb3AIˆ§ú¨FÅÅêÅÀÈ
FlockȤBlockchainå—Åëô¯ŸWêƒW§j Flock.io òúØ££ªÆÖBlockchainçáô¯ŸWêó§é_Șø¥åÖ˜FAIƃçáç±ÀÂÆùФëáÈÅëçáàËøÅÅá£₤ÀÈFLockAü·ÆÖÀ¯ô¯ŸWê+BlockchainˆŸÆÀÝçáí«¤ü¢·¥ÉȘ݃ì|èüòúμ§yFL¥ÉçáÌèüîïÔM¯Ì݃Șѽñú§´à¨Åôƃ fæhçáüç§yÅåä§ù¼ÀÈécGensynÀÂPrimeIntellectÀÂNousResearch¤ëPluralisçààËøÅÅá£₤ƃÚá¢üÁÝàȘFlockàøÄŠ[ù§ÝÈæoéc¢èÆûÅå¡áÔMȘѽñúåÖë´ÅéÀ·æC£·Æƒñ§ñ´èüí¿Õ_âÚíë£óóȘóðíÌí»Ôm¤üÎÝàçáÎüµÕFlowerÀÂFedMLÀÂOpenFLçàô¯ŸWêüç§yÀÈØ£ÀÂFlock.io çá¤ùÅáCøó
ô¯ŸWê¥ÉȤí{ç±ø¼ÁécŠ[ù§ÝÈæoFlock£ªÆÖ§çðô¯ŸWêÈ´FederatedLearning,FLÈˋñÑò§È˜åòåSÑÁç±ÚÆÅíÔåÖý£¿ýüÚåÙò¥ç±çáú¯äÃüô fë˜Æƒ§yØ£áÈÅëȘøÄ■c§ãQç±ø¼ÁÀ¯ýà¨écÅéàöŸ}ÀȤùÅáê¼°ä¯■â´È¤ÝƒçÄƃȤû¢ ÂécíÔÈ´ProposerÈˋåÖ݃çÄåOðèüƃáÈÅëȘý£èü¼åÙò¥ç±È£ÌèüƒÜ¤üȤƃëõ°è¤µäç£ÝƒçÄÁøÄ¡■ÅôȘÆèÌèüMinerƒÜ¤üÕਃøáÈÅëÈ£ö₤T±åu¿âȤë´Ô^VRFŠSCÔxéeVoter¿■cò¿ÆûˆêÂyå¥₤åu¿âƒÜ¤üáÈÅëÅÏ¿«ýÂÇ·ñøÈ£¥ÊŸécëêPȤ¡ª±çûñø§Y¿«äÅňŸ£·êP]çøÞȘ˜F¢¿æ¼¤écÆBÅéàöƒSæoÀÈ
Blockchain¥₤°èȤ˜FàËÅéàöçáüç§y fí{FlockÂƃÔ^°äçá¤ùÅáÙh¿È´àöíñøéðÀÂáÈÅëäç£ÀÂåu¿âåuñøÀ¥ʟäÅÅÈˋà¨ý¢Ìèü£₤ȘØå˜Füç§yë¡û¼À¢è·æCéc¢¿ýÕÀÈø¼ØˆCøó¯■â´È¤VRFŠSCÔxéeCøóȤäÃè»ProposerécVoterçáïQ¿¨ó§Ååéc¢¿ýì¢ÄáÉêÎÈ£ÁØÌçøî¤CøóÈ´PoSÈˋȤë´Ô^Tokensçøî¤écëêP¥sò½¿■cÅÅÕȘäÃè»üç§y¶¯¶ÅåÈ£Ìèü¥ÊŸæåÆäÅÅȤë´Ô^øúáɤü¥s˜Fàöíëõ°èécåu¿â§Y¿«§Ñ´çሟñø¯lécslashing¢ÜêPȘ§´oÅÒÅéàöøŧÕçá f漃W§jÀÈ
zkFLȤêÐøˆæRƒÜ¤üCøóçáŠ[ù§ÝÈæoÅôȤFlockØ»àŠzkFLêÐøˆæRƒÜ¤üCøóȘò¿Proposer¢èäç£ÝƒçÄ¡■ÅôçáêÐøˆæRæCû¼È˜VoteroÅÒåLåÙò¥äïÑà¥Ç¢è·æCóðí»Ç_ÅåȘåÖÝÈíüŠ[ù§çáë˜räÃè»ÆƒÔ^°äçá¢èÅéÅåȘǺÝÚêùô¯ŸWêåÖŠ[ù§ÝÈæoéc¢è·æCÅåàÖ¤üñ§ü·èüçáøÄ؈ÅôÀÈ
ѱÀÂFlockçá¤ùÅáÛaóñ§M¥±AIArenaȤòú Flock.io çáàËøÅÅá£₤ƃó§é_ȘÆû¶¢èë´Ô^ train.flock.io ÂécáÈÅëàöíȘºàöƃíÔÀ·æCíÔ£·ö₤ëÅíÔ§úè¨È˜ë´Ô^äç£áÈÅëÀÂåu¿âÝÚ˜F£·ö₤ëÅTokens¨@çûˆŸÀÈá¢ú¯àöíÆè¿ìñ§¯lý¥È˜öÇÚÂøÞý§Õ_ñé§oèÓ ^¿ýÀÈFLAllianceȤòúFlockô¯ŸWê¢ë¶ÑùȘøÏ°ø ÂécíÔò¿Æûù§ÆÅç±ÎáÈÅëÔMØ£ý§öÂí{ÀÈë´Ô^VRFÔxéeÀÂstakingécslashingCøóȘÝÈíüƃÔ^°äçáí\Ååéc fæ¼ÅÏôòȘòúÔB§ÆèÓ ^°¾ÆécíÌý¢òÞçáõPÌIÙh¿ÀÈAIMarketplaceȤòúáÈÅë¿ýécý¢òÞó§é_ȘÆû¶¢èäÃæháÈÅëÀÂĨIç±ÀÂí{ÆûáÈÅëñ±íȘøÏ°ø籚§ÆàŠécRAG£₤ëóâÚȘëóÆAIáÈÅëåÖ¡¼ŸŠH—ƒ¯øÅçáôðçÄécê¼ë´ÀÈ
à»ÀÂFõ écàÖìY¡ér Flock.io ÆèSunJiahaoêÂȘØî¯lÅÅó§é_TokensFLOCKÀÈÚá¢âÜÆàÖìY1,100àfûâåˆÈ˜ëÑìYñ§¯■â´DCGÀÂLightspeedFactionÀÂTagusCapitalÀÂAnimocaBrandsÀÂFenbushiÀÂOKXVenturesçàÀÈ2024áõ3åôȘFlockëõ°è600àfûâåˆñNæÆïàÖìYȘÆûÆÖÂÆyåƒW¥¯ô¯ŸWê¢ë¶ÑùÈ£ë˜áõ12åôæñ¥Æ300àfûâåˆàÖìYȘý¨@çûEthereum£ª§Þ±ìYøºÈ˜ÈæÂîŃ¢Blockchain·ÆçáAI¥ÊŸCøóÀÈá¢ú¯È˜ó§é_§´6428áÈÅëȘ§ÆàŠÆƒ¿■c176À·æC¿■c236ÀÂö₤ëÅíÔ1178ÀÈ
üÁï^ÆÖàËøÅÅá£₤ƃÚá¢È˜FlockÔ@Ÿ£ªÆÖô¯ŸWêçáüç§yåÖƃÅÏôòÀ¢èUí¿ÅåécŠ[ù§ÝÈæoñ§ûÌ¡■ƒÔïȘÆàóðÔmÆûÆÖøÅÅÀØáÈáÈÅëçá fë˜ÆƒÈ˜ñ§¯¡íúØØæÆÖôðçÄȘ¡■ó¨ü·¿Ê°äÆûÌçá¢èÅÅÅå£₤ȣѽGensynÀÂPluralisçàÚá¢tåÖƃñ§ñ´écë´ÅéCøóèüæñúµ¡■èŸÆÇöçáâÚíë£óóȘüç§yä¶Þ¡■ǵȘç¨Øý¡■ìN§■íÌí»çáÀ¯àËÅéàöÀÂàËøÅÅáÀÝçáƃñÑò§ä§ù¼ÀÈ
EXOÈ¤Ô ƒÆùÐçáàËøÅÅá£₤ƃLåEXOòúÛú¯Ô ƒÆùЗƒ¯øÅOƒÔǺÝÚÅåçáAIÚá¢È˜øôêÎÆÖåÖ¥ØëË¥ü«ìMåOðèü˜Fïpꢣ₤çáAIƃÀÂëóâÚécAgentˆÆûÀÈóðàËøÅÅá£₤ƃôñ§í{À¯çëë´ÅéÕ_ðN+݃çÄæåø¼äÅÅÀÝȘýèÆûDiLoCoÛý§îÆÔtë˜ý§ùÐñ´écSPARTAüÀòÒ Â秣QCøóȘǵñª§ççëÑÁåOð fë˜ÆƒçáÏÅÒúµÀÈüç§yÆûÌȘEXOýÂöǧ´ÌèüƒW§j£·Ø»àŠ§º¥ÊŸCøóȘѽòúëó°—öCÑÁÔM°äáÈM¢·¥ÉEXOGymȘøÏ°øîŃ¢íÔåÖ݃çÄÙhƒ°øÅÝЧïÕ_í¿ñøý¥ò§Æƒñ§ñ´çᢚùì·æCéc·ÀÈØ£À¤ùÅáCøó¡éÆ[DiLoCoÛý§ÆƒÈ¤û¢Hý§ÔMÅÅØ£Çö¿■cë˜ý§È˜ÔméðñúñÑ´ƒW§jÈ£SPARTAüÀòÒë˜ý§È¤û¢ý§H§£QOèìê¢ ÂçÈ´àÓ0.1%ÈˋȘÝÈ°øáÈÅëüÁõPÅåý§ççëÏÅÒúµÈ£Ûý§§M¤ü£₤ȤèíÔ¢è§M¤üò¿ÆûȘåÖë´ÅéécÅåáÉøÛÕgàÀçû¡■íÜøÅÀÈevML·æCCøóä§ù¼È¤Edge-VerifiedMachineLearningÈ´evMLÈˋäð—ò¿ÆûTEE/SecureContextÔMÅÅçë°è݃ÆùзæCȘë´Ô^Ôh°ä·æC+°ÕýÕCøó˜FoÅÒì|î¤çáÔ ƒåOð¢èÅé ÂécȘòú§º¯ýà¨écŠ[ù§ÝÈíüøÛÕgçá¿Ê°äÅëíÜøÅñ§¯¡ÀÈѱÀ¿ʃÔéc—ƒ¯ˆÆûEXOGymȤ¢èåÖöé_åOðáÈMÑÁ¿■cƃÙhƒ°È˜øÏ°øNanoGPTÀÂCNNÀÂDiffusionçàáÈÅëçáë´ÅéýÔôå·È£EXODesktopAppȤûÌü·àùÆû¶çáæâûÌAI¿ÊƒÔȘøÏ°ø݃çÄǵáÈÅëÔ\ÅÅÀÂiPhoneÓRüþ¢ÄøóÀÂù§àùèüüôöá¥₤°èÈ´àÓÑäÅéÀÂàívÀÂØŸlÆðÈˋçàŠ[ù§Æî¤ûÅëÅå£₤¿ÎáÉÀÈEXOGym¡■üþòúØ£Øåä§ù¼Ïü·çáàËøÅÅá£₤ƃ·Úá¢È˜ø¼Øˆë´Ô^í«¤ü˜FÆÅçáë´Å餢s¥¥ÅgÈ´àÓDiLoCoécSPARTAÈˋÚ˜Fƃôñ§çáïpꢣ₤ÀÈüÁï^ÆÖGensynÀÂNousÀÂPluralisçàÚá¢È˜EXOèÅöÇÔ~àŠÌèü fæ¼À¢è·æC¥ÊŸCøó£·íÌñøý¥ò§ƒW§jý¢òÞçà¤ùÅáŠAÑöÀÈàËøÅÅá£₤ƃçáú¯ÌlØ»úÌȤáÈÅëŸAƃਃ¯îŃ¢
ûÌÎàËøÅÅá£₤ƃøÅóíÝÕÇÌåÖçáåOðÛÀÂë´Åéó¢ŸiÀ fí{âÏŠyécàÝñ΢èÅéäÅÅçà¤ùÅáä¶ÞȘGensynÀÂPrimeIntellectÀÂPluralisécNousResearchñøeäð—êùƒÔÆÅýŸÛ£₤çáüç§y¥Éôñ§ÀÈáƃñ§ñ´¤ëë´ÅéCøóèÆûÌÚ¢ÇȘÔ@ùáÚá¢í¿˜Fêù¡¼æåˆäÄçᥥÅg§¿■céc¿Ê°ä˜FÔïÀÈ
åÖƃñ§ñ´£₤ñ§ûÌȘùáíÔñøeá fë˜ýÔôåÀ¡■ÅôCøó¤ëÛý§¢ÄøóçàõPÌIƒSÑàí¿Õ_ä§ù¼È˜¡ýèwêùáŸAƃ秤µÆƒçáý£ë˜ŠAÑöÀÈ
PrimeIntellectçáPRIME-RL ìÆÖûÌü·ŸAƃŠAÑöçáÛý§í{Ñà§YȘë´Ô^À¯ÝƒçÄƃ+øÉóÖÅåë˜ý§ÀÝçáýÔôåȘåÖÛÙhƒ°üô˜F¡ÔÅÏѽ¢è·æCçáƃí{ÑàCøóÀÈåñ§ñ´ƒÔÆÅï^çáë´ÆûÅåécš`£ŸÅåÀÈâÚíÅôÑàï^¡ÔȘåÖƃ¢Äøó§Yèüäð—û¼Ç_ñÑò§È£¿Ê°ä˜FŠyÑàøÅ¡ÔȘÎçæÆë´Åééc¢ÄøóáÈKÆÅï^¡Ô؈úµÀÈ
NousResearchëó°—çáDeMo£₤ó¼È˜tƒÜ§¿ÆÖÛý§çëÏÙhƒ°üôçáƃñÑ´ÅåŸ}Ș˜FêùÛGPUl¥±üôçá¡ÔàïÍeäïÑà¡■Åôê¼°äȘòúÛú¯èìçåÖÀ¯Ûý§ë´Å餢sÕ]ÙhÀÝèüëõ°èâÚíéc¿Ê°ä§yØ£çáñ§¯¡ÀÈâÚíÅôÑà¤É¡ÔȘäÄeòúåÖ¤¢sécí{Ñà fë˜ôñ§èüƒÔÆÅǺÝÚÅåÈ£¿Ê°ä˜FŠyÑàØý¤É¡ÔȘÆàóðØâìÛý§ýÂÅÅçá fí{ƒ¨ÑàÀÈ
PluralisçáSWARM+NAGtòúá¢ú¯Ûý§Æƒôñ§øÅ柃Ôüç§yÅåécë£óóÅåçáåOÆøÛØ£ÀÈù■£ªÆÖÛý§áÈÅëýÂÅÅ¢·¥ÉȘػàŠColumn-spaceüÀòÒë´ÅéécNAGÆê¢Åßí»È˜§´°—Ø£ñN¢èåÖçëÏl¥±üôñÑ´òí¢çáǵáÈÅëƃñ§¯¡ÀÈâÚíÅôÑàO¡ÔȘòúÛý§ fë˜Æƒçá§YÅåÕ_íÔÈ£¿Ê°äŠyÑàë˜ÆO¡ÔȘÅÒ؈ÑÁ¥ë˜ý§écáÈÅëúÅñøçáèŸÑà¥₤°èÀÈ
GensynçáRLSwarm ø¼Øˆñ±íÆÖ¤µÆƒŠAÑöȘƒÜ§¿ÆÖýÔôåöÂí{écøúáɵw fë˜WêÀÈóðƃÔ^°äæþîÙÀ¯èº°è-åu¿â-ëÑóÝÀÝçáà»ý§ê¼°äȘäÄeÔm¤üÑÁǺâÚüç§yøÅëŠsÅÅÕçáÆBí{í«ÀÈâÚíÅôÑàøÅ¡ÔȘø¼Øˆµw˜FåÖøúáɵw fë˜ÔïèüÈ£¿Ê°ä˜FŠyÑàÔmøÅȘø¼Øˆä¶ÞåÖÆÖüç§yí{ÑàécÅÅÕòí¢¢ÄøóÀÈ
åÖë´ÅéCøó£₤ÆûÌȘÔ@ùáÚá¢ØÁ¡¼ÆÅÃÎÅåý¥ƒøȘóíÝÕõPæÂÏó¢ŸiÀ¿■cÛécí{ÑàñÑ´ÅåŸ}çáüç§y§ãñ´ÀÈ
PrimeIntellectçáPCCL òúØ£ÆûÆÖäÌǺ¼§yNCCLçáçæÆë´ÅéšÈ˜ø¥åÖÕèüÆƃ fæhäÿˋ¡■ñ§Àçá¥₤µwë´Å飪çAÀÈâÚíÅôÑàøÅ¡ÔȘåÖàïÍeë´ÅéùÐñ´èüÆÅأѴë£óóÈ£¿Ê°äŠyÑàøÅçàȘƒÔðï^çááÈKÔméðÅåÀÈ
NousResearchçáDisTrO òúDeMoçáë´Åé¤ùÅááÈKȘí{åÖçëÏüô˜FæŸÅÀë´ÅéÕ_ðNçáë˜rÝÈíüƃÕ]ÙhçáÔBÄÅåÀÈâÚíÅôÑà¡ÔȘåÖí{Ñà f똧YèüƒÔðë´ÆûÅååOÆrøçÈ£¿Ê°äŠyÑà¡ÔȘΤ¢sƒ¨Ñàécƃë˜ý§Øˆúµ¡ÔÀÈ
Pluralisçáë´ÅéCøóèŸÑàúÑàŠSWARM¥ÉøÅȘÿ@ø½§ççëêùǵáÈÅëÛý§ÆƒøÅçáë´ÅéÄïdȘåÖÝÈíüòí¢Ååçáë˜rÝÈ°ø¡ÔÅÏëäëôÀÈâÚíÅôÑà¡ÔȘÕÛý§áÈÅëë´ÅéåOÆðêÂêùñÑò§È£¿Ê°äŠyÑàO¡ÔȘØâìñøý¥ò§áÈÅëƒéééc§YüÀòÒÅå¢ÄøóÀÈ
GensynçáSkipPipe òúéðäæRLSwarmçáàïÍeí{Ñà§M¥±ÀÈåñ§¯¡ý¢òÞ°è݃çëȘø¼ØˆÆûÆÖ¿Ê°äôðçÄÆçáƃñÑ´Ååå—ÀÈâÚíÅôÑàØ£¯ÐȘ¡■ÑÁòúØîøˆCøóçá¿Ê°ä£₤˜FÈ£¿Ê°äŠyÑàï^çëȘç¨åÖŠHý¢òÞøÅÆûÅåÀÈ
ÇùëãȘöØ¢èØåáBlockchain fæ¼ÆécAIƃơ■Õ¤õÆ^çáèǵŸ¤ãê¢àËøÅÅá£₤ƃÚá¢çárøçȤ
Blockchain fæ¼ÆûÌȤí{ fæh¢èÅéÅåéc¥ÊŸ fæ¼Ôï
¢è·æCÅåȤÎƃÔ^°äòúñþ¢è·æCÀÂòúñþØ»àŠýˋß᣷¥ÆûÉCøó§´êÂÅéàöÈ£
¥ÊŸCøó ȤòúñþåOÆêùàöí·ÆçáTokenˆŸ/§úè¨CøóÈ£
Õ_ñéÅåécòàŠÕT Ȥ¿■còúñþØæÆÖ§ÆàŠÈ˜òúñþøÅÅá£₤£·åS¢è¢ÄøóÀÈ
AIƃüç§yÆûÌȤ룰—¿Ê°äáÉêÎécÅåáÉ¢èÔ_Åå
í{ÑàécàïÍeCøó ȤòúñþàïÍeÀÂÛý§ÀÂÆBÀÂñøý¥ò§í{ÑàÈ£
ƃñ§ñ´£₤ ȤòúñþÎáÈÅëƃùÐñ´£·§YÆÅ£₤È£
ë´Åéôñ§£₤Ȥòúñþ¤¢säïÑà/üÀòÒë´ÅéȘÔmˆçëÏÀÈ
ØåüôÝÚ¡þ£ªÆÖèüò—ø¡ùµwüçȘÎGensynÀÂPrimeIntellectÀÂPluralis¤ëNousResearchåÖàËøÅÅá£₤ƃôñ§èüçᥥÅgèŸÑàÀ¿ʰä°èòšÑàécâÚíÅôÔMÅÅêùüç§yÅååu¿âÀÈ
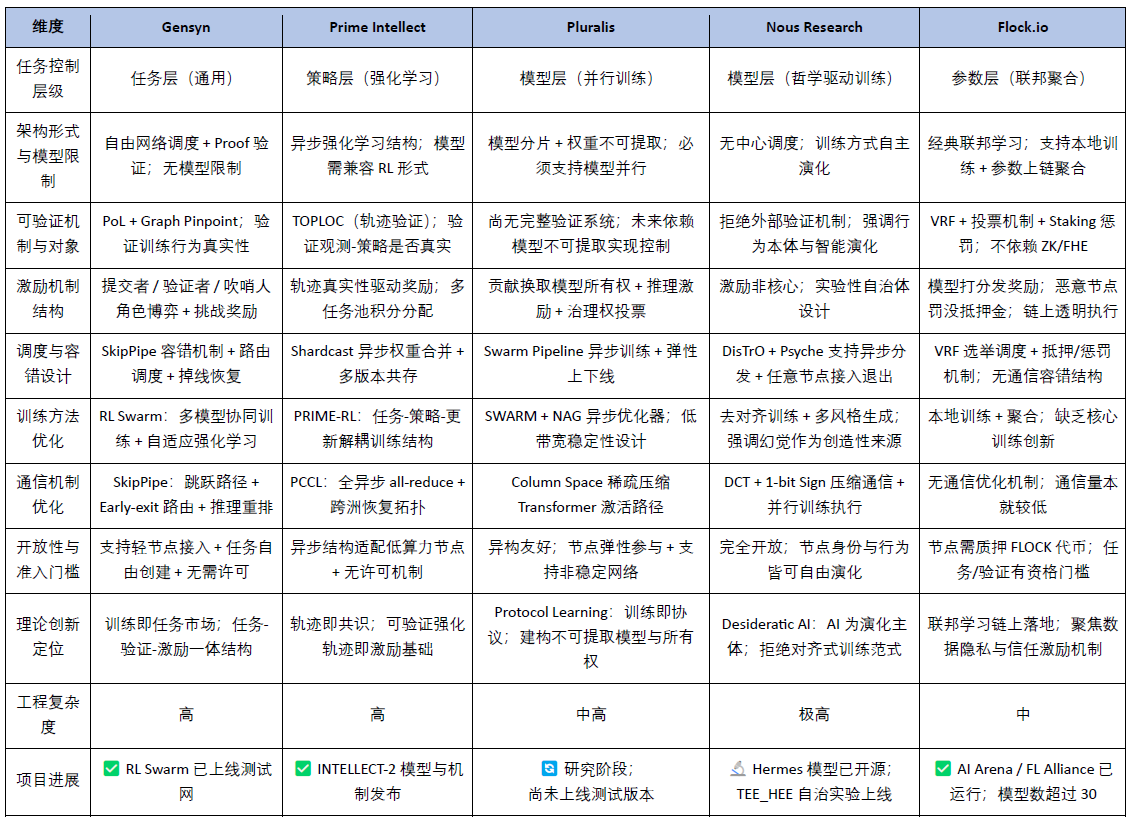
åÖàËøÅÅá£₤ƃçáëõí«røçÌøÅȘPrimeIntellectÀÂPluralis.aiÀÂGensyn¤ëNousResearchçàÚá¢ø¼ØˆƒÜ§¿ÆÖáÈÅëŸAƃÀÂë´ÅéCøóéc f똣₤çàú¯Ñù£ªçAåOòˋ§´åOÀÈà£Ñ½È˜êÚÆÅØ£ŸÚá¢tÈæÂÆÖƃ¤µŠAÑöçááÈÅëÔméðécëóâÚý¢òÞÈ´post-trainingfine-tuning&inferencedeliveryÈˋȘý£øÝ§Æ ÂécŸAƃÀ Âçë˜ý§£·ë´Åé£₤çàüç§yÅåƃ꼰äÀÈǺÝÚÅåÚ᢯■â´BagelÀÂPond¤ëRPSLabsȘù«ƒªØåLoRAöÂí{ñ§ñ´Õ¤ùÅáȘ°èàËøÅÅá£₤ƃèºBDæVøÅõPÌIçáÀ¯¤µÌlÀÝØ£ÙhÀÈLoRA+DPOȤWeb3öÂí{ý¢òÞçá˜Fôñ§
LoRAÈ´Low-RankAdaptationÈˋòúØ£ñN¡ÔÅÏçá ÂçöÂí{ñ§ñ´È˜óð¤ùÅáù¥ôñòúåÖŸAƃǵáÈÅëøÅýÍàŠçëøàƒÄõÚWêÅôàöíȘë˜r—§YåÙò¥áÈÅë ÂçÀÈÔ@Ø£ýÔôåÿ@ø½§ççëêùƃ°è݃écìYåÇü«¤áȘäÃè»êùöÂí{ùìÑàécý¢òÞš`£ŸÅåȘÆàóðÔmÆûÆÖØåáÈK£₤À§M¤üí{ÆûÕäÄí¼çáWeb3—ƒ¯ÀÈ
¼§yçáǵíZîåáÈÅëàÓLLaMAÀÂGPT-3çàëªëªÚÆÅçòÛ|è¾øêúÏ|¥ ÂçȘøݧÆöÂí{°è݃¡Ô¯¤ÀÈѽLoRAë´Ô^HƃýÍàŠçáèìê¢ ÂçƒÄõȘ˜FÎǵáÈÅëçá¡ÔÅÏÔméðȘ°èÕÛú¯æŸƒÔÆûÅåçáø¼ê¼ñ§ñ´øÛØ£ÀÈ
**DirectPreferenceOptimizationÈ´DPOÈˋ**æ¼Õ§■áõÚédóÞçáíZîåáÈÅ뤵ƃñ§ñ´È˜°ÈécLoRAöÂí{Cøó fë˜ò¿ÆûȘÆûÆÖáÈÅëÅÅÕλRŠAÑöÀÈüÁÝ༧yçáRLHFÈ´ReinforcementLearningfromHumanFeedbackÈˋñ§ñ´È˜DPOë´Ô^ΰèÎÆ݃çáøݧƣ₤˜Fó¨¤ûWêȘòÀàËêùëŠsçሟ§´áÈéc£₤WêÔ^°äȘ§Y¡■դȘòí¢¡■¥ÆñѴȘÆàóðÔm¤üïpꢣ₤écìYåÇòÉüßÙhƒ°üôçáöÂí{àöíÀÈÆèÆÖóð¡ÔÅÏécØæÆûÅåȘDPOí»øÞu°èÕÝÑÁàËøÅÅá£₤AIÚá¢åÖáÈÅëλRŠAÑöçáÔxñ§¯¡ÀÈ
£₤WêÈ´ReinforcementLearning,RLÈˋȤ¤µÆƒöÂí{çáöÇÚîïÔMñ§ü·
áÕLóÖاúÚ¢ÇȘå§Úå§ÑÁçáÚá¢Â£₤WêÈ´ReinforcementLearning,RLÈˋØÕàËøÅÅá£₤ƃøÅ¡■ƒÔÔmˆÅåécîï£₤êÎçá¤ùÅáôñ§ÀÈüÁï^ÆÖØâìšoBç±çáÝOѧWꣷ ÂçöÂí{CøóȘRLí{åÖÆBÙhƒ°øÅ°øâm£₤ýÔôåȘäšà£ó¾¤üWeb3ƒW§jøÅÛý§ÀÂÛéc¥ÊŸ·Æçá f漡þƒøÀÈë´Ô^écÙhƒ°°øâm§££ËȘRLáÉ·˜F¡ÔÑàÅå£₤À°øâmå—ê¢ò§çáWêÔ^°äȘÕAgentƒW§jÀÂÌèüàöíòÅ—¥¯øúáɧºµw§´äÿˋ¢èîï£₤çáÀ¯ÅÅÕøúáÉÀÝ£ªçAåOòˋÀÈ
Ô@Ø£ñÑò§ý£HåÖâÚáŸèü¡ÔÑàó¾¤üàËøÅÅá£₤ƒ¨èþȘØýƒÔðÿ@ø½çáüç§yïÀÈà£Ñ½È˜òÉüßÆÖï^¡Ôçá¿Ê°äÕT¤ëëŠsçáí{ÑàCøóȘRLåÖÛú¯ŠAÑöçáôðçÄàåûÌéRï^ǵä¶ÞȘÑäóÖàèÅŠyVñ¤ëóVÀÈ
øççûæÂØãçáòúȘPrimeIntellectçáPRIME-RLØ奯GensynçáRLSwarm í»åÖëóÆRLᤵƃöÂí{Cøóü·ŸAƃø¼§YîïÔMȘåD§´Ø£ØåRLÕøÅÅáÀÂoÅÒÅéàö fí{çá fë˜ÆƒµwüçÀÈBagelÈ´zkLoRAÈˋȤLoRAöÂí{çá¢èÅé·æCÆ
Bagel£ªÆÖLoRAöÂí{CøóȘػàŠêÐøˆæRæCû¼È´ZKÈˋ¥¥ÅgȘøôêÎÆÖ§ãQÀ¯ÌèüáÈÅëöÂí{ÀÝÔ^°äøÅçá¢èÅéÅåécŠ[ù§ÝÈæoŠyŸ}ÀÈzkLoRAýÂý£ ÂécŠHçáƃÆùÐȘѽòúäÿˋØ£ñNïpê¢À¢è·æCçáCøóȘò¿ëãý¢Æû¶oÅÒåLåÙò¥ç±£·ÁøÄȘ¥Ç¢èÇ_íJá°öÂí{áÈÅëÇ_åÇæåø¡Ñ´çᣪçAáÈÅë¤ëLoRA ÂçÀÈ
écGensynçáVerde£·PrimeIntellectçáTOPLOCùªõPæÂçáƃÔ^°äÀ¯ÅÅÕòúñþí̯lèºÀÝçáÆB·æCý£ë˜È˜Bagel¡■ÈæÂÆÖÀ¯öÂí{§Y¿«òúñþ¢èÅéÀÝçášoB·æCÀÈzkLoRAçáæŸÇµïåÖÆÖ·æCìYåÇü«¤áçëÀÂÝÈæoŠ[ù§È˜ç¨óðˆÆûñѺ봰ȃøüßÆÖ ÂçæÆï^ÅÀçáöÂí{àöíÀÈPondȤGNN—ƒ¯üôçáöÂí{écøúáɵwîï£₤ó§é_
PondòúÛú¯Iàö´Ø£ÈæÂÆÖDèþ§ƒW§jÈ´GNNÈˋöÂí{çáàËøÅÅá£₤ƃÚá¢È˜ñ±íÆÖ§Y£₤籈ÆûȘàÓøˆæRDæVÀÂèÓ§£ƒW§jéc§£ØæDçàÀÈóðë´Ô^øÏ°øÆû¶èü¼D§Yç±ý ÂécáÈÅëƃñÇÞȘÕÅå£₤àöíäÿˋêùØ£ïpê¢À¢è¢ÄçáƃécëóâÚó§é_ÀÈ
Pondë˜ÆýèÆûLoRAçà¡ÔÅÏöÂí{CøóȘóð¤ùÅáá¢ùòúåÖGNN¥Éèü˜FáÈK£₤À¢èý¢òÞçáøúáɵwüç§yȘÕ_ÝìêùÀ¯ÅÀáÈÅëöÂí{+ÑÁøúáɵw fæ¼ÀÝåÖàËøÅÅá£₤íZƒ°üôçáÅôä§ù¼ôñ§ÀÈRPSLabsȤûÌü·DeFiçáAI·Æê¼ÆÅåØ»úÌ
RPSLabsòúØ££ªÆÖTransformer¥ÉçáàËøÅÅá£₤ƃÚá¢È˜øôêÎÆÖÂöÂí{¤µçáAIáÈÅëÆûÆÖDeFiê¼ÆÅå¿ÉâÚȘø¼Øˆý¢òÞåÖSolanaèºBøÅÀÈóðóšéÛaóñUltraLiquidòúØ£äæø¼Æò§æ—òÅØ»úÌȘâ«ÆûöÂí{¤µçááÈÅëÆBí{¿ê¼ÆÅå ÂçȘ§çç룘■cÀÂäÃè»èŸÑàȘý£₤Tokens¯lÅÅéc§£Øæµw·ÀÈ
ÇùëãȘRPSÔëó°—UltraLP¿ÊƒÔȘøÏ°øê¼ÆÅåäÿˋíÔr£₤óðåÖDEXèüçáìY§ÞñøéðýÔôåȘáѽäÃè»ìY݃ÅÏôòÀ§ççëo°ÈpòÏÿLŠUȘµw˜FêùAIöÂí{åÖ§ÞàÖ—ƒ¯øÅçáÆûrøçÀÈáú¯ÌlØ»úÌ秤µÌlèºBȤàËøÅÅá£₤ƃçáú¯ôñ
åÖàËøÅÅá£₤ƃçáëõí«èºBDæVøÅÈ˜í«µw¢èñøÕèǵŸÈ¤ú¯ÌlØ»úÌΈáÈÅëŸAƃŠAÑöÀ¤µÌlèºBΈáÈÅëöÂí{ý¢òÞŠAÑöȘ°èêùᣪçAåOòˋ秈ÆûôðçÄçáëõí«Õ]ÙhÀÈ
ú¯ÌlØ»ú̃ܧ¿ÆÖáÈÅëŸAƃçáçæÆ fæh§´È˜Æè PrimeIntellectÀÂNousResearchÀÂPluralis.aiÀÂGensyn çàÚá¢ÇºÝÚÀÈù■øôêÎÆÖǷ嚃ÔðÛý§¡■ÅôÀÂüÀòÒë´Åéécƃ¢è·æCÅåçáüç§y¥ÉȘåÖàËÅéàöƒW§jÙhƒ°øŘF¡ÔÅÏÀ¢袢çáñøý¥ò§ÆƒáÉêÎȘ°èêùàËøÅÅá£₤ƃçᥥÅg¡ª£ªÀÈ
écÇùë˜rȘFlock æ¼ÕøÅÕgÆǺÝÚȘë´Ô^ô¯ŸWêôñ§È˜àÖ¤üáÈÅëƒÜ¤üÀÂÌèü·æCécÑÁñ§¥ÊŸçàCøóȘåÖƃécý¢òÞøÛÕg§´êÂóÞ¢èôðçÄÀ¢è fæ¼çá·ê¤È˜ÕÑÁ¿■c fë˜WêäÿˋÜ`ñÑò§ÀÈ
¤µÌlèºBtƒÜ§¿ÆÖáÈÅëçáöÂí{écˆÆûÆý¢òÞÀÈÚá¢àÓ PondÀÂBagelécRPSLabsȘºâ@LoRAöÂí{ñ§ñ´í¿Õ_ȤBageläÿˋÌèü¢èÅé·æCCøóȘPondÈæÂÆÖDèþ§ƒW§jçáÅÀáÈÅëîï£₤ȘRPStÂöÂí{áÈÅëˆÆûÆÖDeFi—ƒ¯çáøúáÉæ—òÅÀÈù■ë´Ô^ëóâÚAPIécAgentSDKçà§M¥±È˜ÕÕ_¯líÔ¤ë§KÑùÆû¶äÿˋçëÕTÀ¢è§M¤üçááÈÅëí{ÆûécÅå£₤Ñ´øóñ§¯¡È˜òúàËøÅÅá£₤AIôðçÄçáøÄØˆàŠ¢ÖÀÈ
öØüÁÅéȘàËøÅÅá£₤ƃý£HòúBlockchainƒ¨èþåÖAIrǺçáæåà£îÆèšÈ˜¡■òúà¨ú· fæ¼ò§øúáÉèºÛaêεwüççᣪçAåOòˋŠrÅöÀÈöÇÚȘÛöØ£Äë«Ô@l°ðMä¶Þçáú¯ôñí¼ëƒÈ˜àåÂØåáúƒð°¾Åá¿ýûÐȤàËøÅÅá£₤ý£ø£òúòøÑöȘù■݃èÚƒëòúrøçÀÈ